浏览器的通信能力
用户代理
浏览器可以代替用户完成http请求,代替用户解析响应结果,所以我们称之为:
用户代理 user agent
在网络层面,对于前端开发者,必须要知道浏览器拥有的两大核心能力:
- 自动发出请求的能力
- 自动解析响应的能力
自动发出请求的能力
当一些事情发生的时候,浏览器会代替用户自动发出http请求,常见的包括:
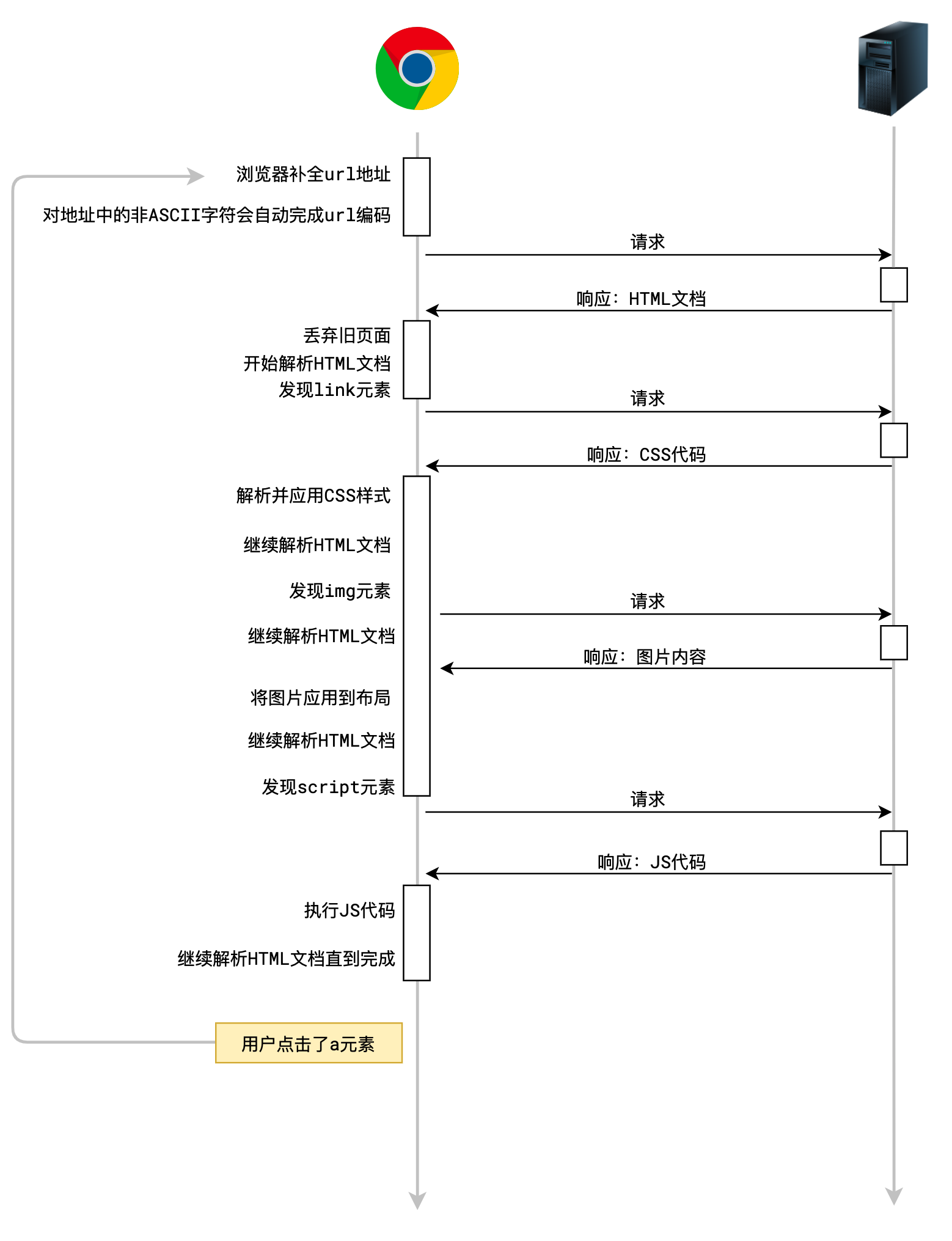
用户在地址栏输入了一个url地址,并按下了回车
浏览器会自动解析URL,并发出一个
GET请求,同时抛弃当前页面。当用户点击了页面中的a元素
浏览器会拿到a元素的href地址,并发出一个
GET请求,同时抛弃当前页面。当用户点击了提交按钮
<button type="submit">...</button>浏览器会获取按钮所在的
<form>元素,拿到它的action属性地址,同时拿到它method属性值,然后把表单中的数据组织到请求体中,发出指定方法的请求,同时抛弃当前页面。这种方式的提交现在越来越少见了
当解析HTML时遇到了
<link> <img> <script> <video> <audio>等元素浏览器会拿到对应的地址,发出
GET请求当用户点击了刷新
浏览器会拿到当前页面的地址,以及当前页面的请求方法,重新发一次请求,同时抛弃当前页面。
浏览器在发出请求时,会自动附带一些请求头
==重点来了==
从古至今,浏览器都有一个约定:
当发送GET请求时,浏览器不会附带请求体
这个约定深刻的影响着后续的前后端各种应用,现在,几乎所有人都在潜意识中认同了这一点,无论是前端开发人员还是后端开发人员。
由于前后端程序的默认行为,逐步造成了GET和POST的各种差异:
- 浏览器在发送 GET 请求时,不会附带请求体
- GET 请求的传递信息量有限,适合传递少量数据;POST 请求的传递信息量是没有限制的,适合传输大量数据。
- GET 请求只能传递 ASCII 数据,遇到非 ASCII 数据需要进行编码;POST 请求没有限制
- 大部分 GET 请求传递的数据都附带在 path 参数中,能够通过分享地址完整的重现页面,但同时也暴露了数据,若有敏感数据传递,不应该使用 GET 请求,至少不应该放到 path 中
- POST 不会被保存到浏览器的历史记录中
- 刷新页面时,若当前的页面是通过 POST 请求得到的,则浏览器会提示用户是否重新提交。若是 GET 请求得到的页面则没有提示。
自动解析响应的能力
浏览器不仅能发送请求,还能够针对服务器的各种响应结果做出不同的自动处理
常见的处理有:
识别响应码
浏览器能够自动识别响应码,当出现一些特殊的响应码时浏览器会自动完成处理,比如
301、302根据响应结果做不同的处理
浏览器能够自动分析响应头中的
Content-Type,根据不同的值进行不同处理,比如:text/plain: 普通的纯文本,浏览器通常会将响应体原封不动的显示到页面上text/html:html文档,浏览器通常会将响应体作为页面进行渲染text/javascript或application/javascript:js代码,浏览器通常会使用JS执行引擎将它解析执行text/css:css代码,浏览器会将它视为样式image/jpeg:浏览器会将它视为jpg图片application/octet-stream:二进制数据,会触发浏览器下载功能attachment:附件,会触发下载功能该值和其他值不同,应放到
Content-Disposition头中。
基本流程
AJAX
浏览器本身就具备网络通信的能力,但在早期,浏览器并没有把这个能力开放给JS。
最早是微软在IE浏览器中把这一能力向JS开放,让JS可以在代码中实现发送请求,并不会刷新页面,这项技术在2005年被正式命名为AJAX(Asynchronous Javascript And XML)
AJAX 就是指在web应用程序中异步向服务器发送请求。
它的实现方式有两种,XMLHttpRequest 简称XHR和Fetch
以下是两者的对比
| 功能点 | XHR | Fetch |
|---|---|---|
| 基本的请求能力 | ✅ | ✅ |
| 基本的获取响应能力 | ✅ | ✅ |
| 监控请求进度 | ✅ | ❌ |
| 监控响应进度 | ✅ | ✅ |
| Service Worker中是否可用 | ❌ | ✅ |
| 控制cookie的携带 | ❌ | ✅ |
| 控制重定向 | ❌ | ✅ |
| 请求取消 | ✅ | ✅ |
| 自定义referrer | ❌ | ✅ |
| 流 | ❌ | ✅ |
| API风格 | Event |
Promise |
| 活跃度 | 停止更新 | 不断更新 |